八、 机器学习和深度学必知算法
1 领略算法魅力
深刻研究排序算法是入门算法较为好的一种方法,现在还记得4年前手动实现常见8种排序算法,通过随机生成一些数据,逐个校验代码实现的排序过程是否与预期的一致,越做越有劲,越有劲越想去研究,公交车上,吃饭的路上。。。那些画面,现在依然记忆犹新。
能力有限,当时并没有生成排序过程的动画,所以这些年想着抽时间一定把排序的过程都制作成动画,然后分享出来,让更多的小伙伴看到,通过排序算法的动态演示动画,找到学习算法的真正乐趣,从而迈向一个新的认知领域。
当时我还是用C++写的,时过境迁,Python迅速崛起,得益于Python的简洁,接口易用,最近终于有人在github中开源了使用Python动画展示排序算法的项目,真是倍感幸运。
动画还是用matplotlib做出来的,这就更完美了,一边学完美的算法,一边还能提升Python熟练度,一边还能学到使用matplotlib制作动画。
快速排序动画展示
归并排序动画展示

堆排序动画展示
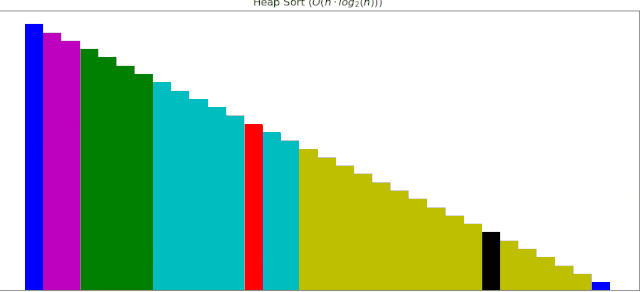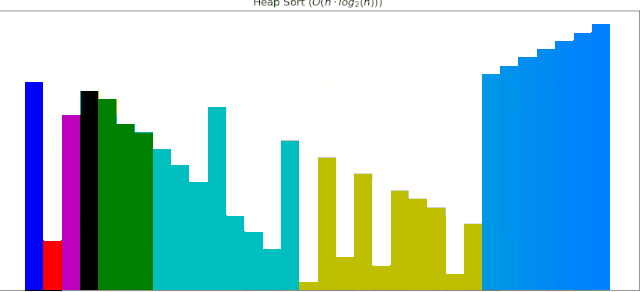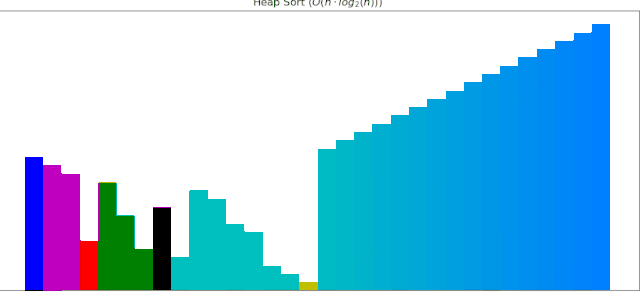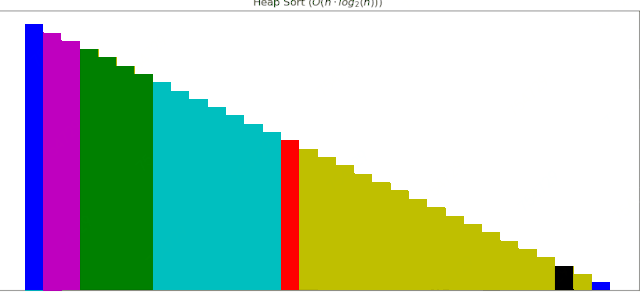
这些算法动画使用Matplotlib制作,接下来逐个补充。
2 排序算法的动画展示
学会第一部分如何制作动画后,可将此技术应用于排序算法调整过程的动态展示上。
首先生成测试使用的数据,待排序的数据个数至多20个,待排序序列为random_wait_sort,为每个值赋一个颜色值,这个由random_rgb负责:
data_count = 20 # here, max value of data_count is 20
random_wait_sort = [12, 34, 32, 24, 28, 39, 5,
22, 11, 25, 33, 32, 1, 25, 3, 8, 7, 1, 34, 7]
random_rgb = [(0.5, 0.811565104942967, 0.11211028937187217),
(0.5, 0.5201323831224014, 0.6660999602342474),
(0.5, 0.575976663060455, 0.17788242607567772),
(0.5, 0.6880174797416493, 0.43581701833249353),
(0.5, 0.4443131322001743, 0.6993600264279745),
(0.5, 0.5538835821863523, 0.889276053938713),
(0.5, 0.4851681185146841, 0.7977608586163772),
(0.5, 0.3886717808488436, 0.09319137949618972),
(0.5, 0.8952456581687489, 0.8282376936934484),
(0.5, 0.16360202854998007, 0.4538892160157194),
(0.5, 0.23233400128809478, 0.8544141586189615),
(0.5, 0.5224648797546528, 0.8194014475829123),
(0.5, 0.49396099968405016, 0.47441724394796825),
(0.5, 0.12078104526714728, 0.7715022079860492),
(0.5, 0.19428498518228154, 0.08174917157481443),
(0.5, 0.6058698403873457, 0.6085936584142663),
(0.5, 0.7801178568951216, 0.6414767240649862),
(0.5, 0.4768865661174162, 0.3889866229610085),
(0.5, 0.4301945092238082, 0.961688141676841),
(0.5, 0.40496648895289855, 0.24234095882836093)]
再封装一个简单的数据对象Data:
class Data:
def __init__(self, value, rgb):
self.value = value
self.color = rgb
# 造数据
@classmethod
def create(cls):
return [Data(val, rgb) for val, rgb in zip(random_wait_sort[:data_count],
random_rgb[:data_count])]
3 先拿冒泡实验
一旦发生调整,我们立即保存到帧列表frames中,注意此处需要deepcopy:
# 冒泡排序
def bubble_sort(waiting_sort_data):
frames = [waiting_sort_data]
ds = copy.deepcopy(waiting_sort_data)
for i in range(data_count-1):
for j in range(data_count-i-1):
if ds[j].value > ds[j+1].value:
ds[j], ds[j+1] = ds[j+1], ds[j]
frames.append(copy.deepcopy(ds))
frames.append(ds)
return frames
实验结果图:
完整动画演示:
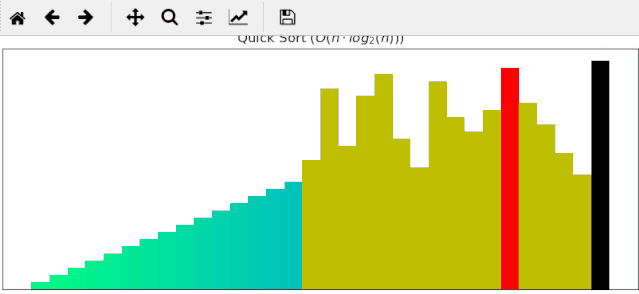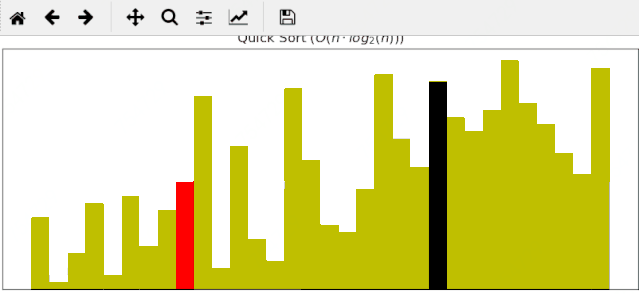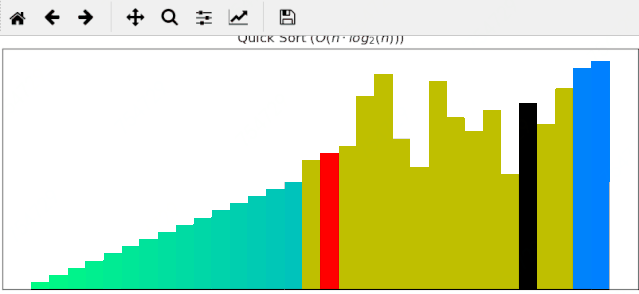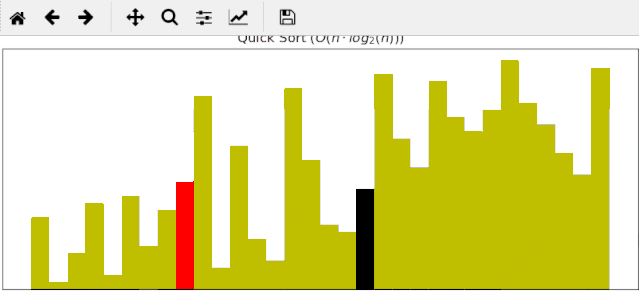
4 快速排序
先上代码,比较经典,值得回味:
def quick_sort(data_set):
frames = [data_set]
ds = copy.deepcopy(data_set)
def qsort(head, tail):
if tail - head > 1:
i = head
j = tail - 1
pivot = ds[j].value
while i < j:
if ds[i].value > pivot or ds[j].value < pivot:
ds[i], ds[j] = ds[j], ds[i]
frames.append(copy.deepcopy(ds))
if ds[i].value == pivot:
j -= 1
else:
i += 1
qsort(head, i)
qsort(i+1, tail)
qsort(0, data_count)
frames.append(ds)
return frames
快速排序算法对输入为随机的序列优势往往较为明显,同样的输入数据,它只需要24帧调整就能完成排序:
5 选择排序
选择排序和堆排序都是选择思维,但是性能却不如堆排序:
def selection_sort(data_set):
frames = [data_set]
ds = copy.deepcopy(data_set)
for i in range(0, data_count-1):
for j in range(i+1, data_count):
if ds[j].value < ds[i].value:
ds[i], ds[j] = ds[j], ds[i]
frames.append(copy.deepcopy(ds))
frames.append(ds)
return frames
同样的输入数据,它完成排序需要108帧:
动画展示如下,每轮会从未排序的列表中,挑出一个最小值,放到已排序序列后面。
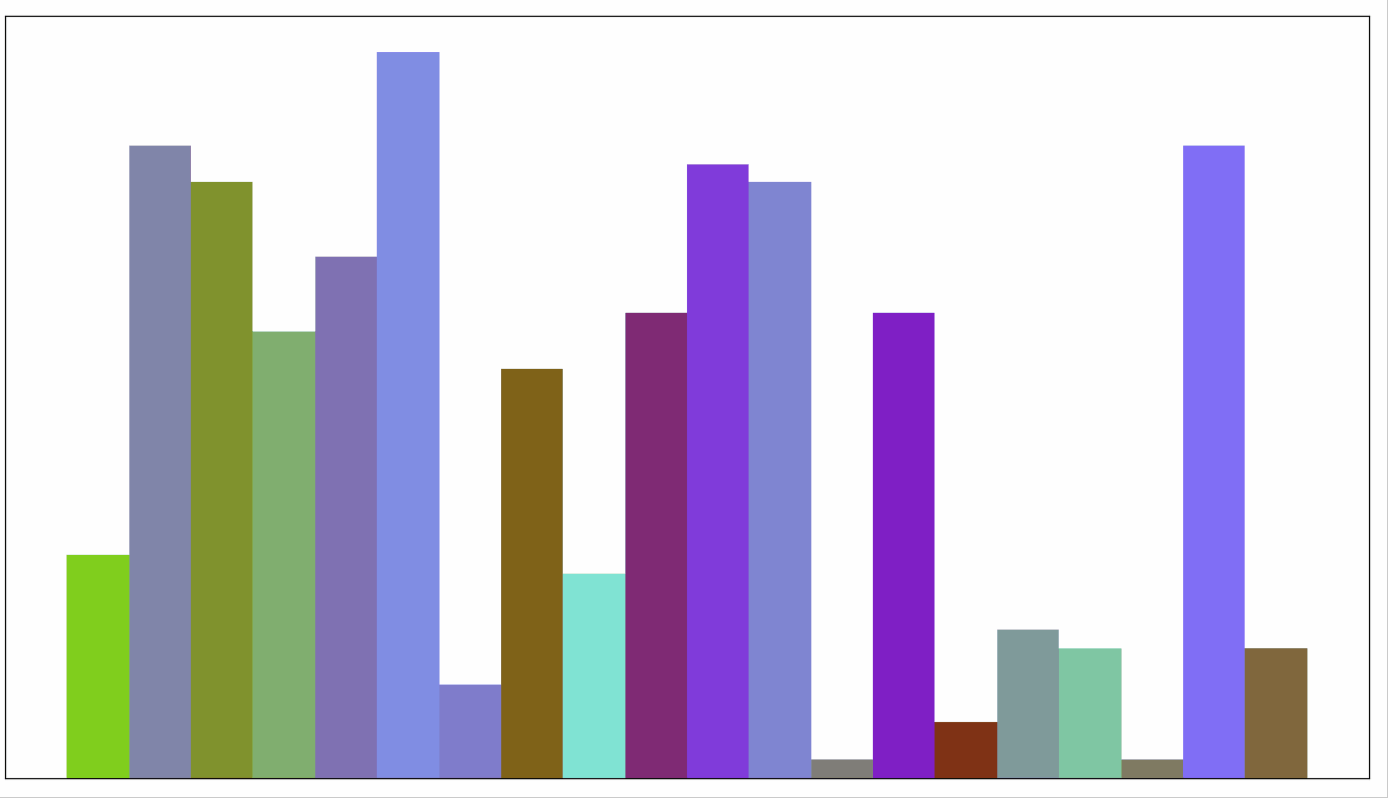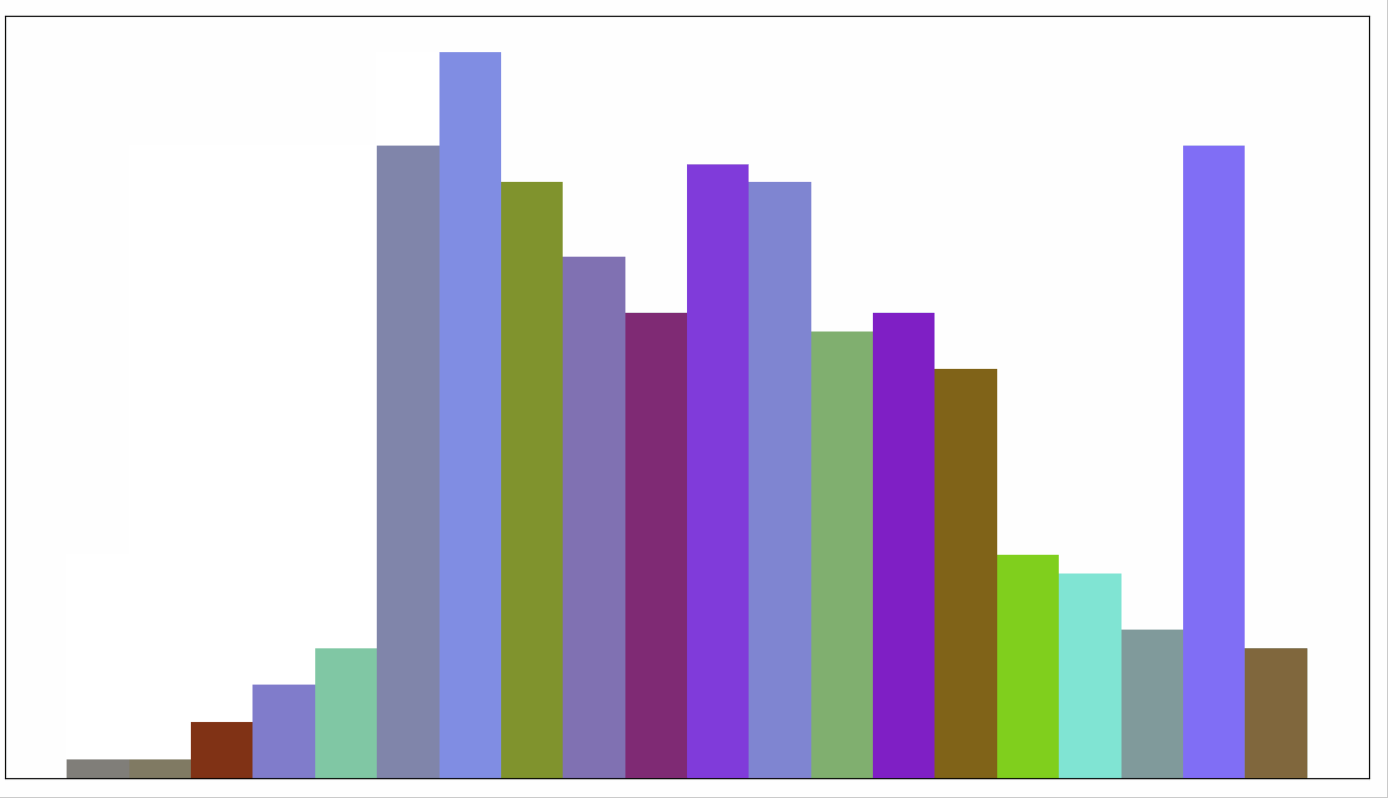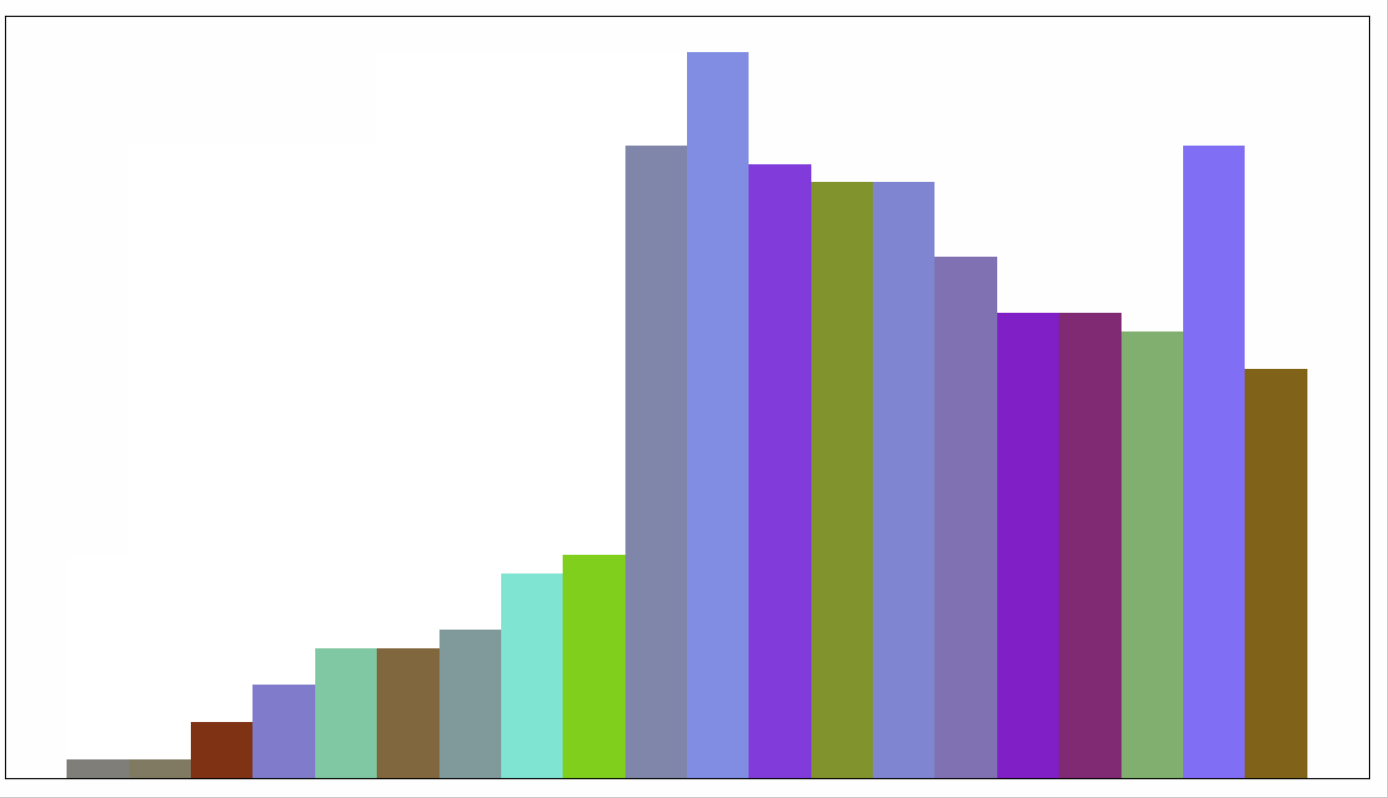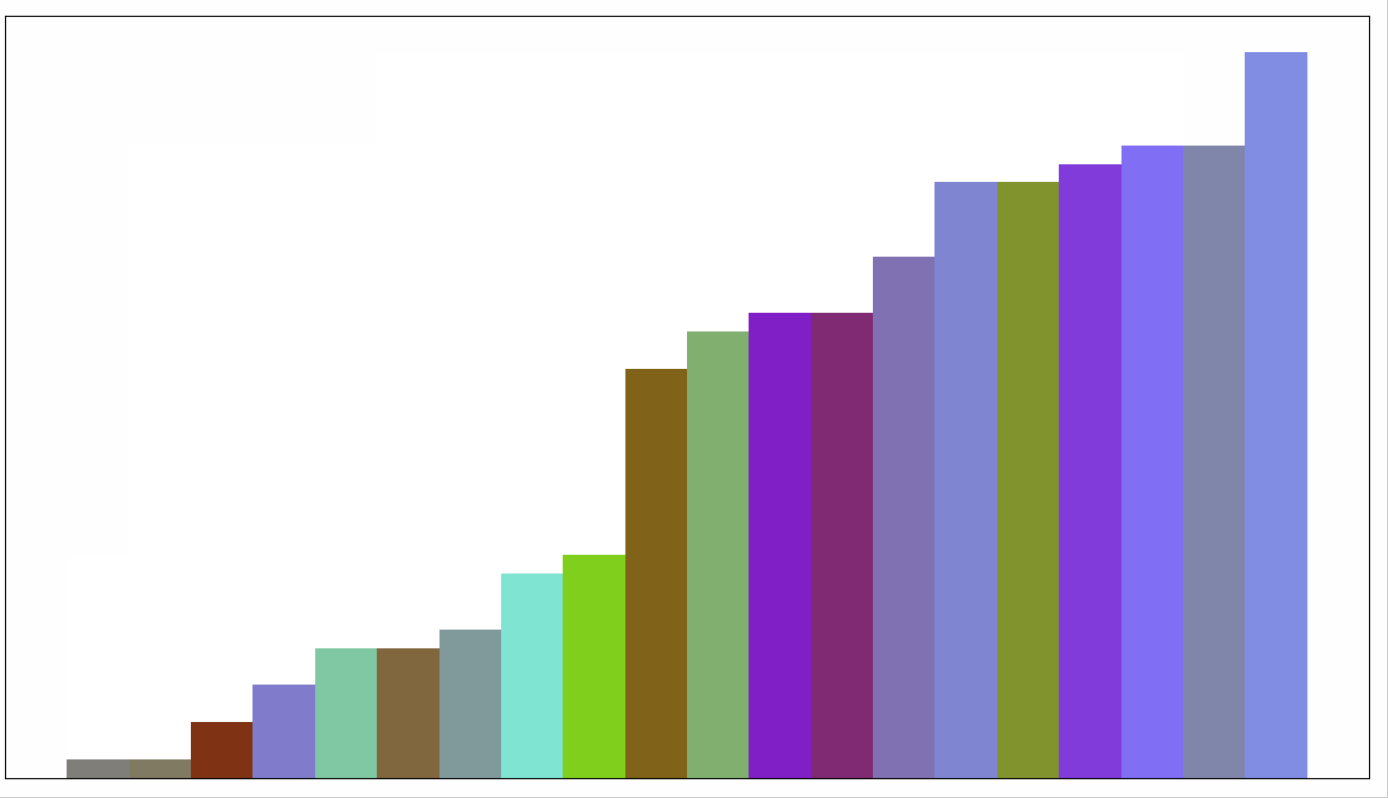
6 堆排序
堆排序大大改进了选择排序,逻辑上使用二叉树,先建立一个大根堆,然后根节点与未排序序列的最后一个元素交换,重新对未排序序列建堆。
完整代码如下:
def heap_sort(data_set):
frames = [data_set]
ds = copy.deepcopy(data_set)
def heap_adjust(head, tail):
i = head * 2 + 1 # head的左孩子
while i < tail:
if i + 1 < tail and ds[i].value < ds[i+1].value: # 选择一个更大的孩子
i += 1
if ds[i].value <= ds[head].value:
break
ds[head], ds[i] = ds[i], ds[head]
frames.append(copy.deepcopy(ds))
head = i
i = i * 2 + 1
# 建立一个最大堆,从最后一个父节点开始调整
for i in range(data_count//2-1, -1, -1):
heap_adjust(i, data_count)
for i in range(data_count-1, 0, -1):
ds[i], ds[0] = ds[0], ds[i] # 把最大值放在位置i处
heap_adjust(0, i) # 从0~i-1进行堆调整
frames.append(ds)
return frames
堆排序的性能也比较优秀,完成排序需要51次调整。
7 综合
依次调用以上常见的4种排序算法,分别保存所有帧和html文件。
waiting_sort_data = Data.create()
for sort_method in [bubble_sort, quick_sort, selection_sort, heap_sort]:
frames = sort_method(waiting_sort_data)
draw_chart(frames, file_name='%s.html' % (sort_method.__name__,))
获取以上完整代码、所有数据文件、结果文件:完整源码下载
9 优化算法
机器学习是一个目标函数优化问题,给定目标函数f,约束条件会有一般包括以下三类:
- 仅含等式约束
- 仅含不等式约束
- 等式和不等式约束混合型
当然还有一类没有任何约束条件的最优化问题
关于最优化问题,大都令人比较头疼,首先大多教材讲解通篇都是公式,各种符号表达,各种梯度,叫人看的云里雾里。
有没有结合几何图形阐述以上问题的?很庆幸,还真有这么好的讲解材料,图文并茂,逻辑推导严谨,更容易叫我们理解拉格朗日乘数法、KKT条件为什么就能求出极值。
10 仅含等式约束
假定目标函数是连续可导函数,问题定义如下:
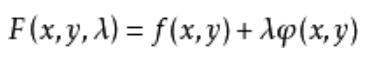
然后:

通过以上方法求解此类问题,但是为什么它能求出极值呢?
11 找找感觉
大家时间都有限,只列出最核心的逻辑,找找sense, 如有兴趣可回去下载PPT仔细体会。
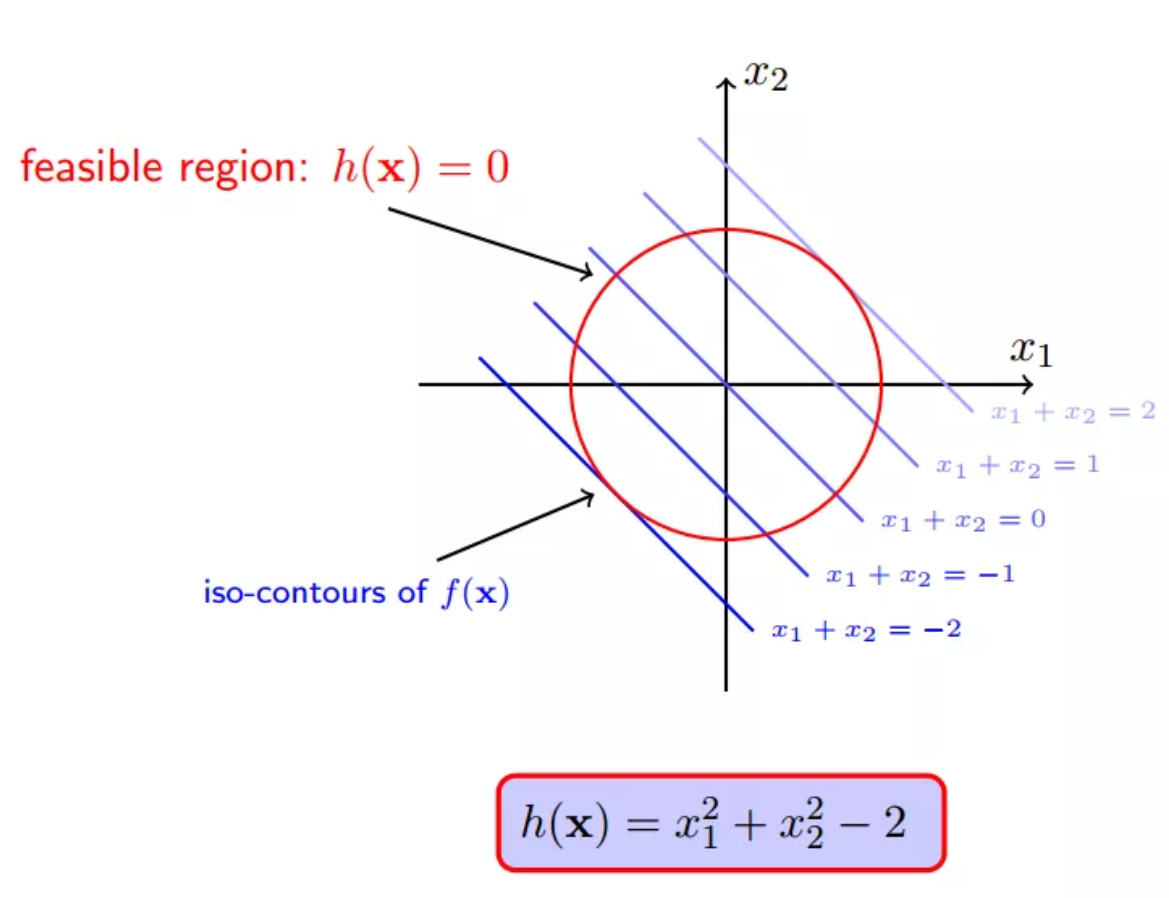
此解释中对此类问题的定义:

为了更好的阐述,给定一个具体例子,锁定:
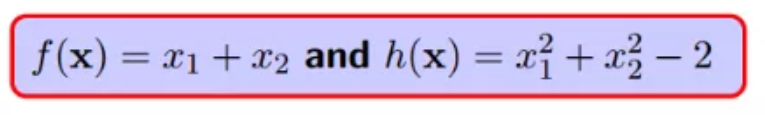
所以,f(x)的一系列取值包括0,1,100,10000等任意实数:
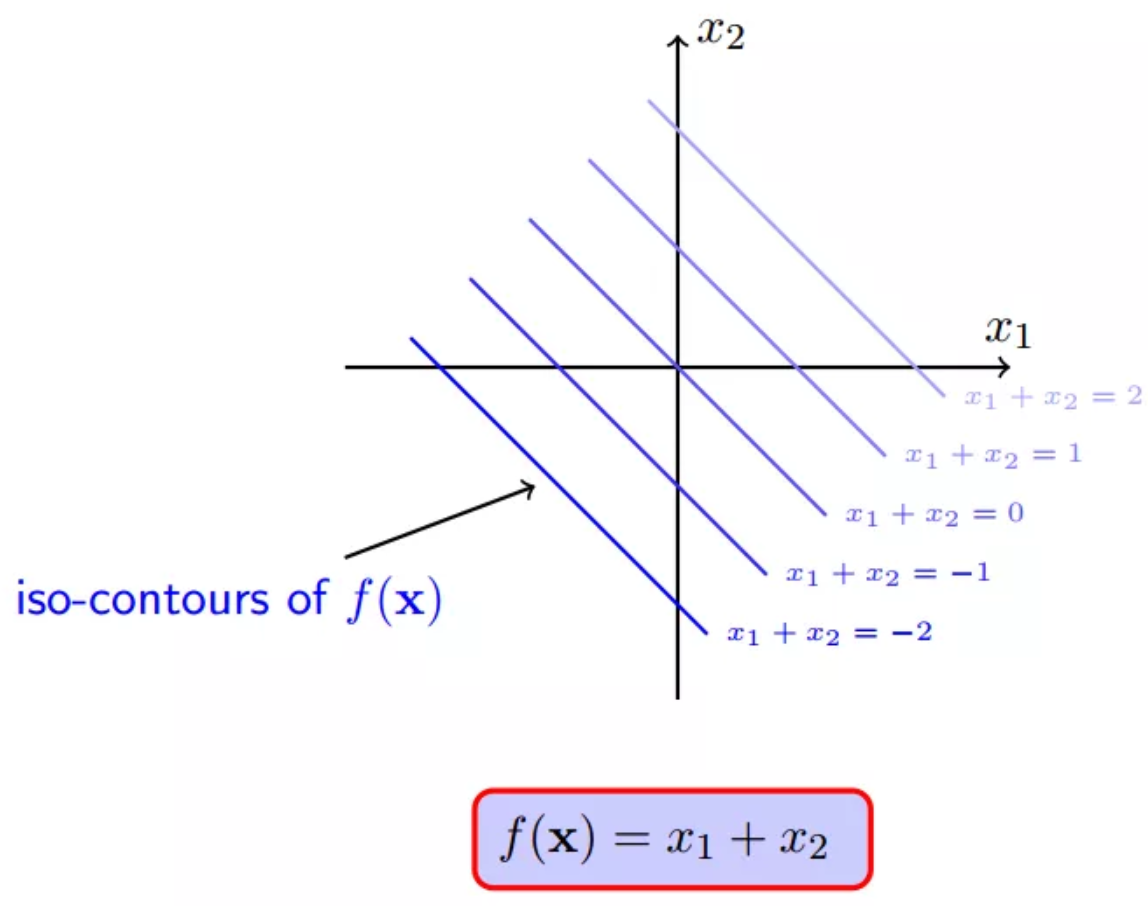
但是,约束条件h(x)注定会约束f(x)不会等于100,不会等于10000...
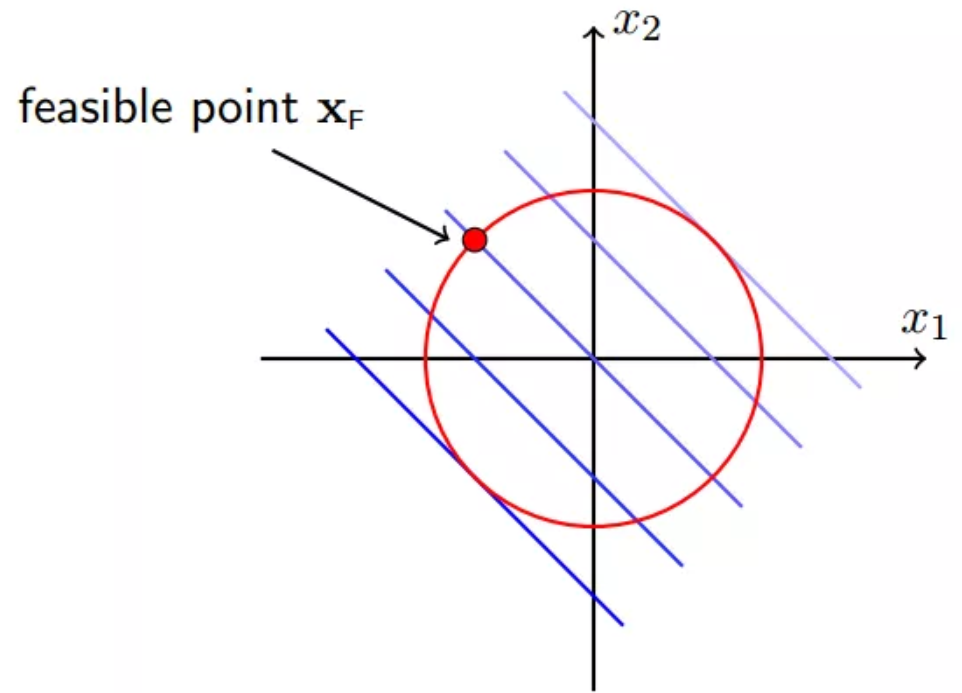
一个可行点:
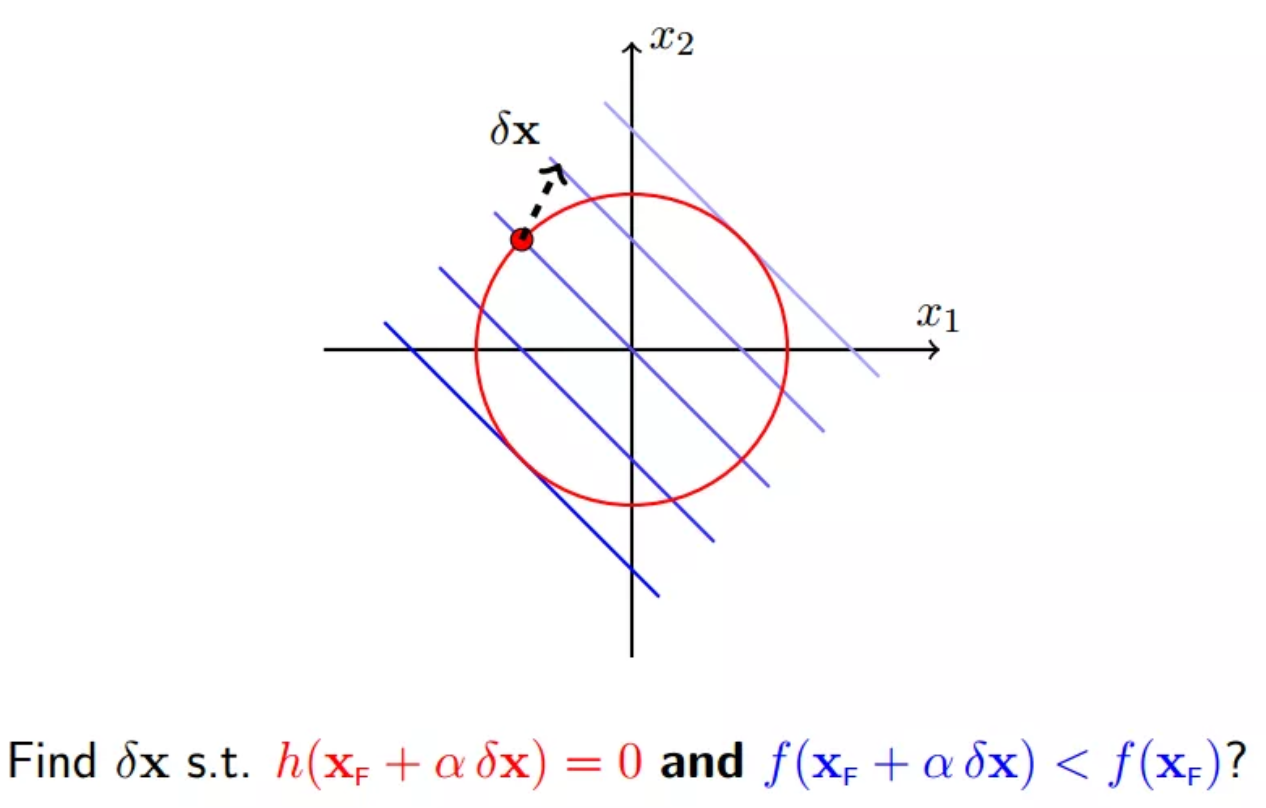
12 梯度下降
我们想要寻找一个移动x的规则,使得移动后f(x+delta_x)变小,当然必须满足约束h(x+delta_x)=0
使得f(x)减小最快的方向就是它的梯度反方向,即
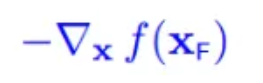
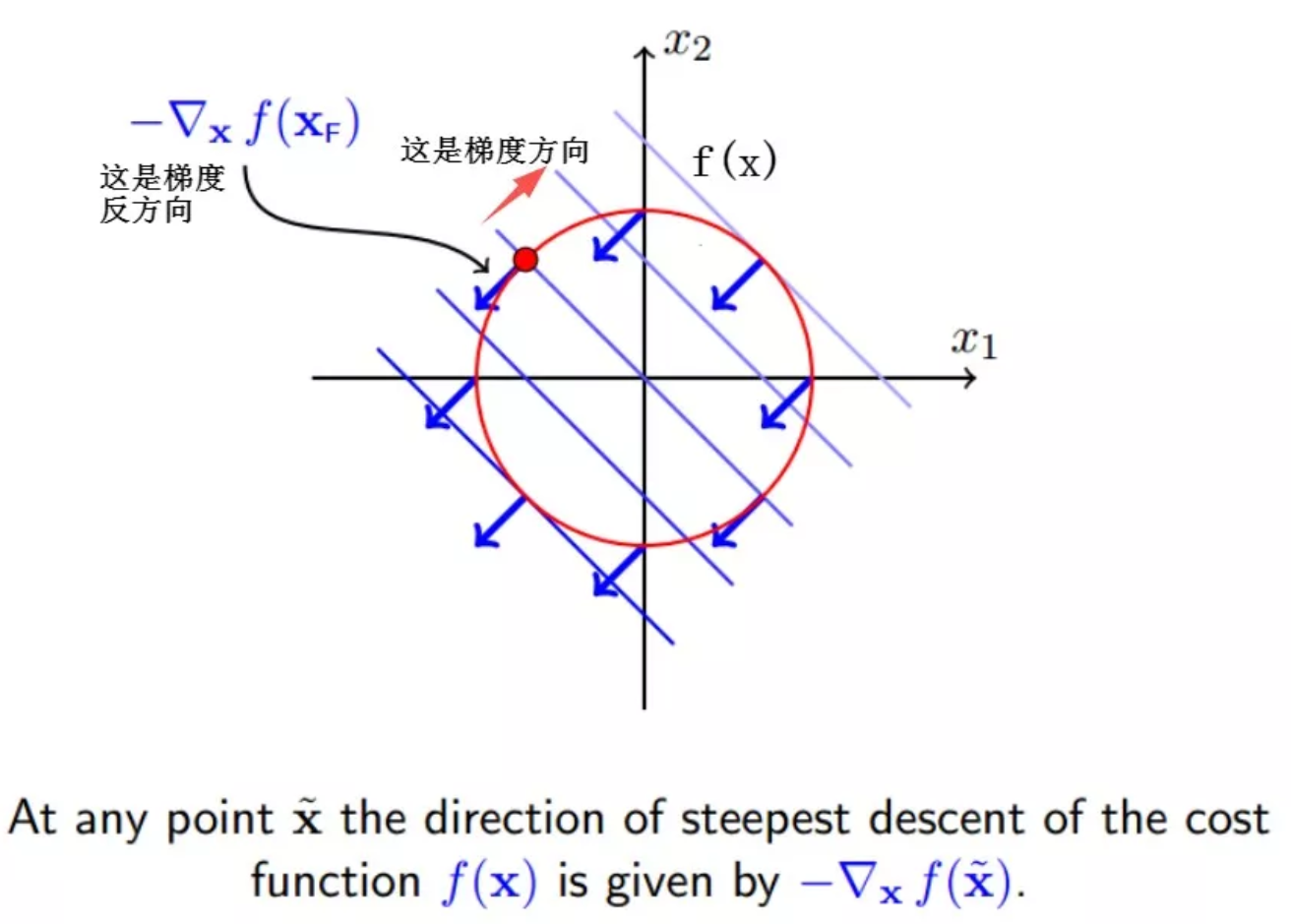
因此,要想f(x+delta_x) 变小,通过图形可以看出,只要保持和梯度反方向夹角小于90,也就是保持大概一个方向,f(x+delta_x)就会变小,转化为公式就是:
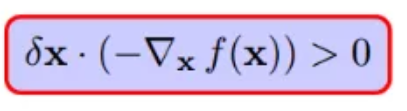
如下所示的一个delta_x就是一个会使得f(x)减小的方向,但是这种移动将会破坏等式约束: h(x)=0,关于准确的移动方向下面第四小节会讲到
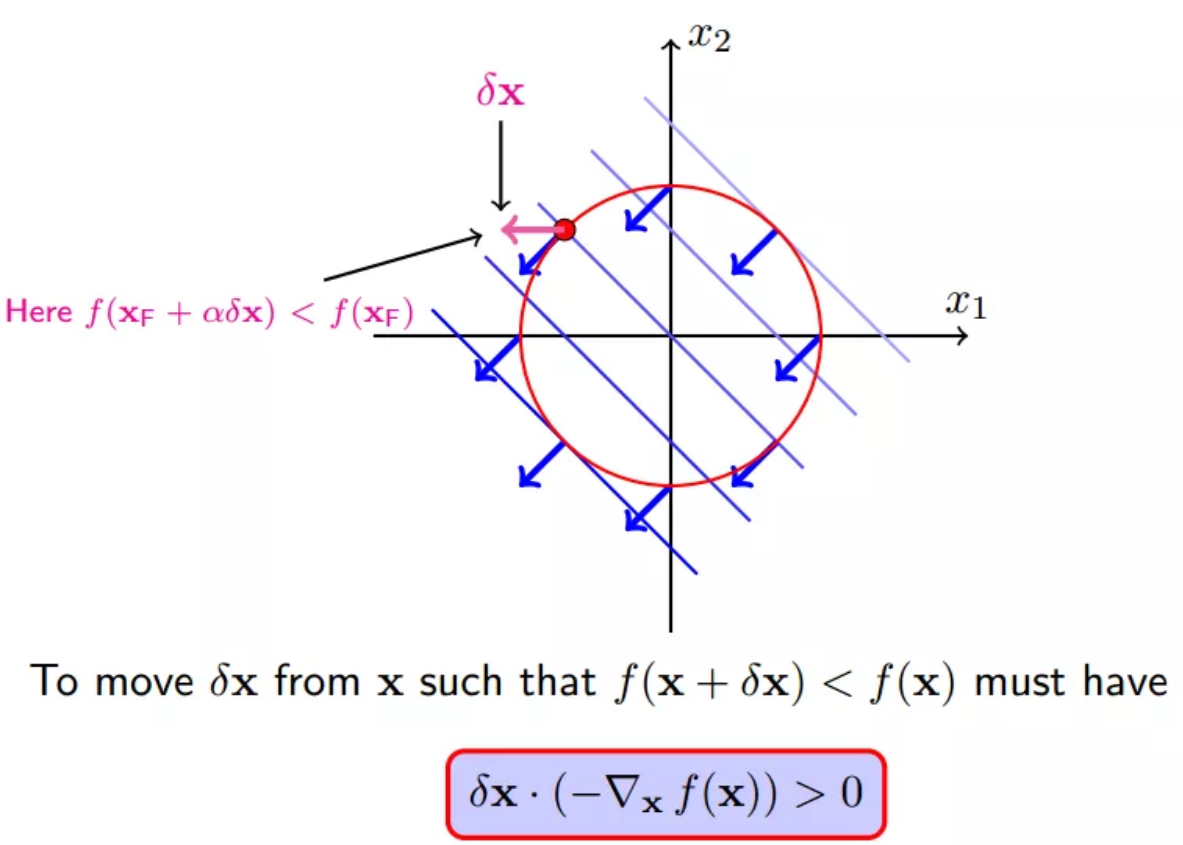
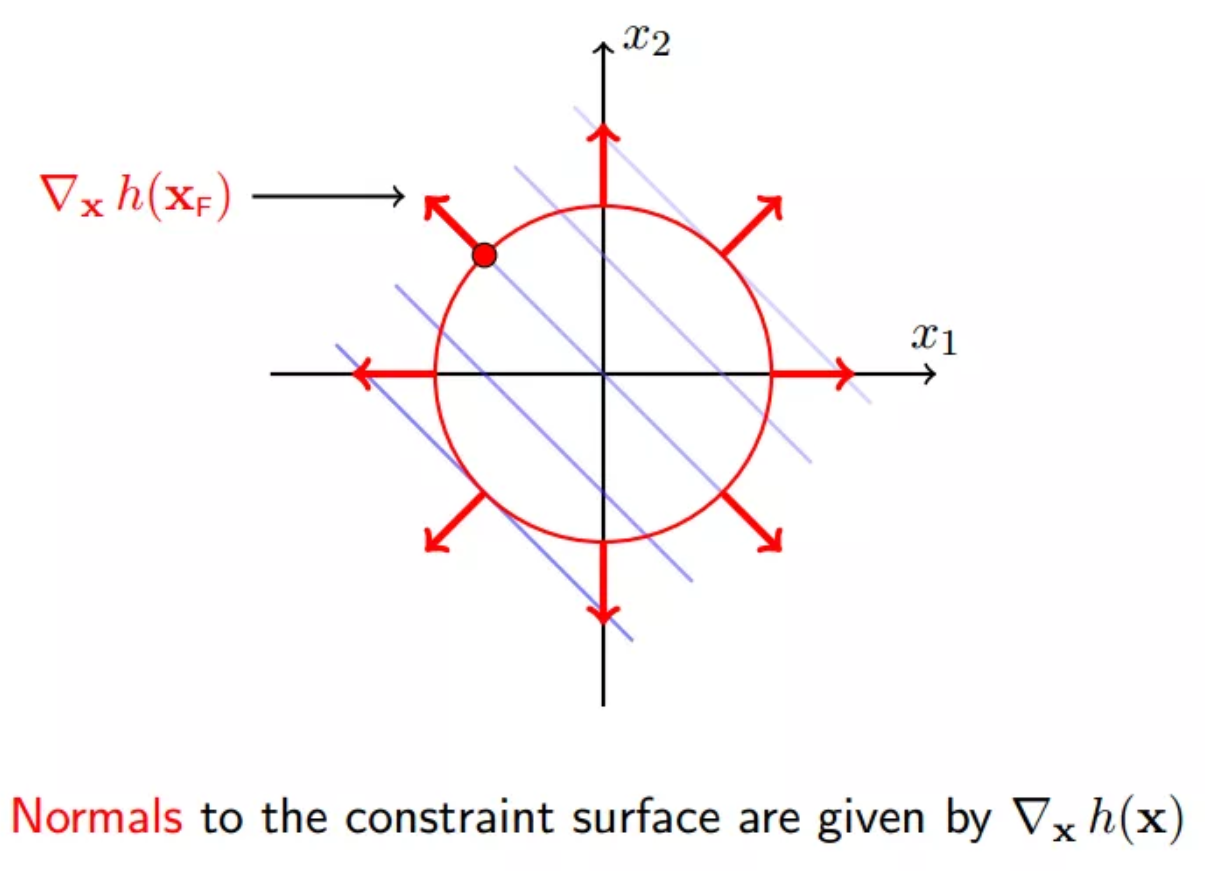
13 约束面的法向
约束面的外法向:
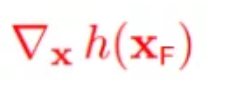
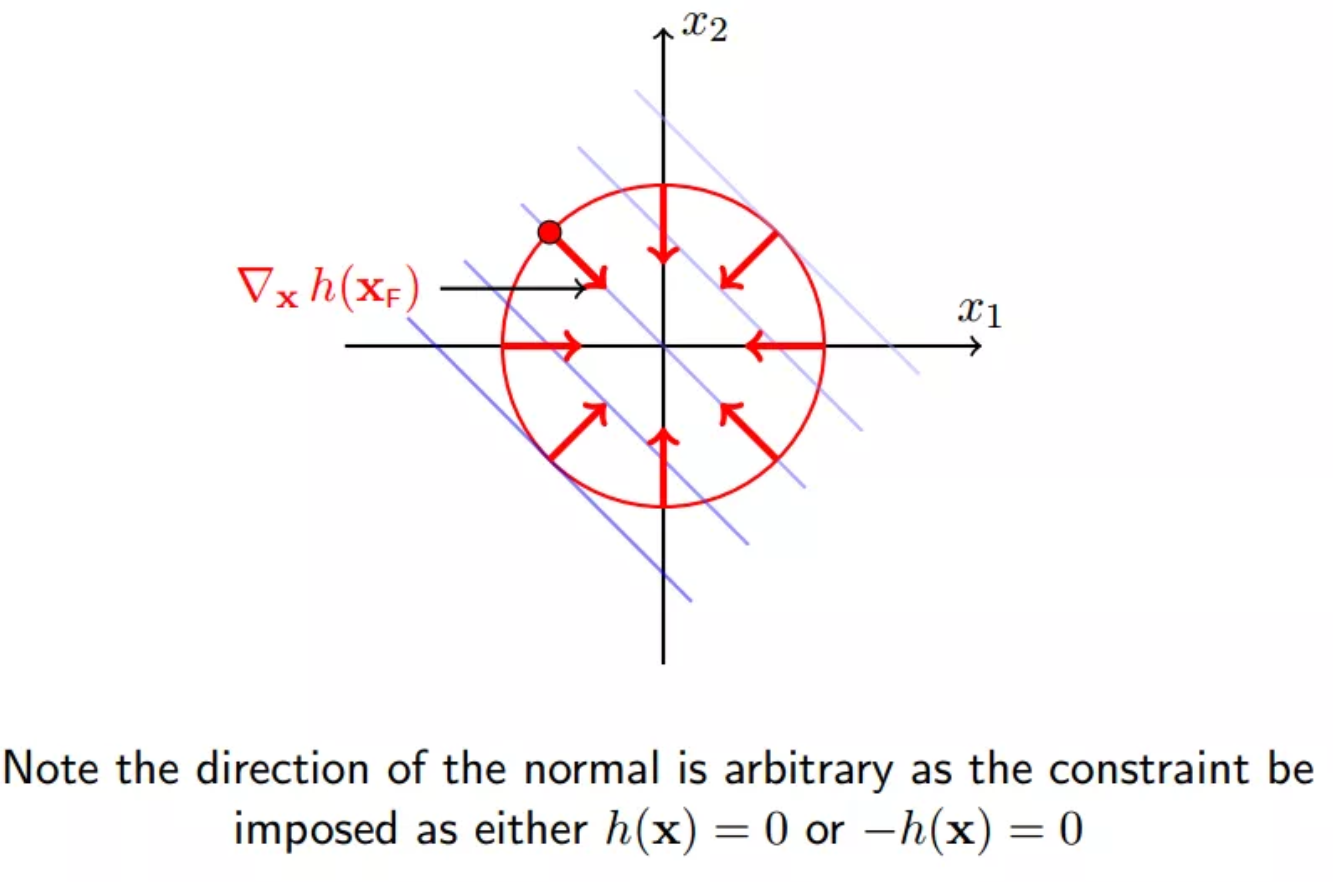
约束面的内法向:
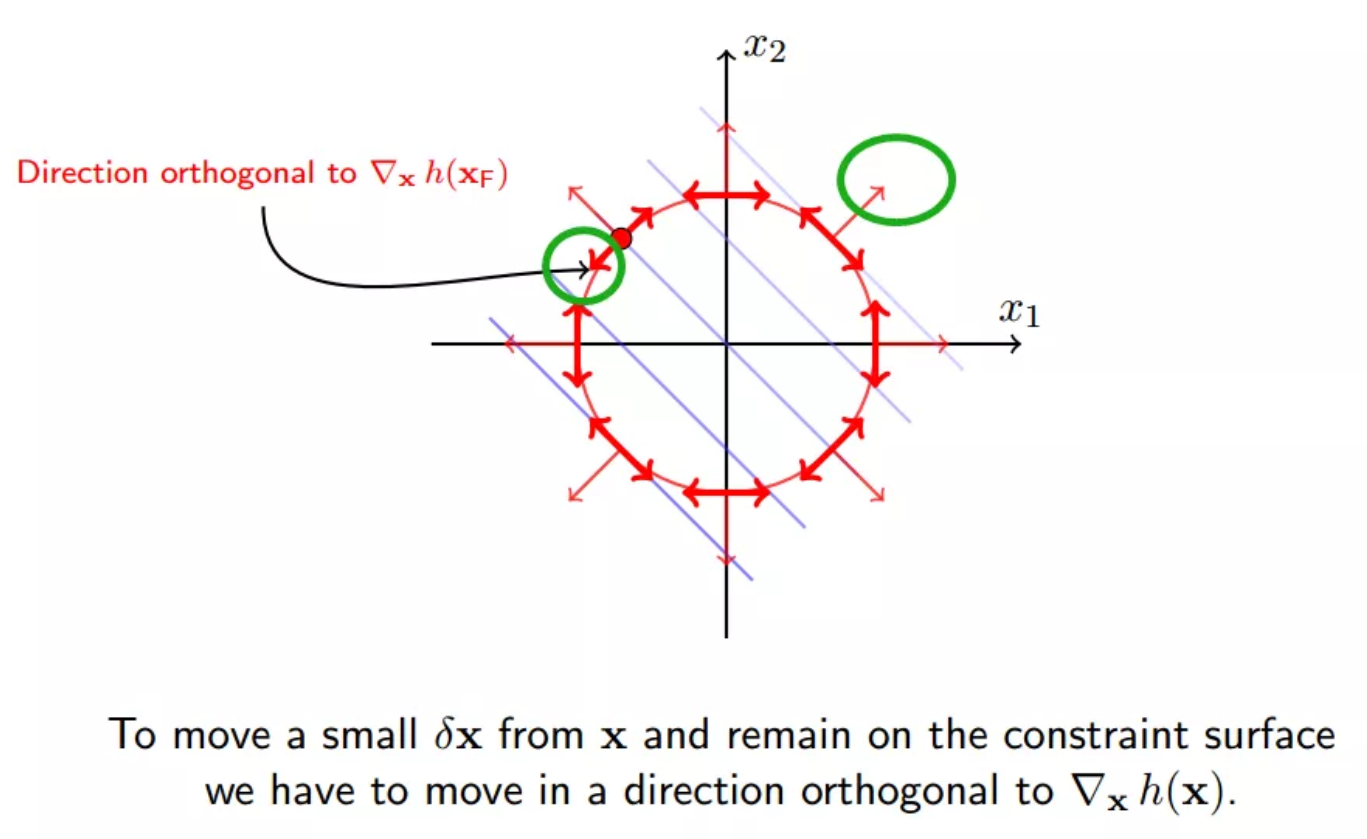
绿圈表示法向的正交方向
x沿着绿圈内的方向移动,将会使得f(x)减小,同时满足等式约束h(x) = 0
14 大胆猜想
我们不妨大胆假设,如果满足下面的条件:
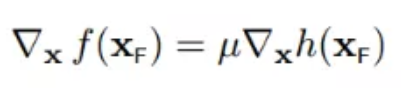
根据第四小节讲述,delta_x必须正交于h(x),所以:
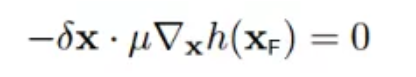
所以:
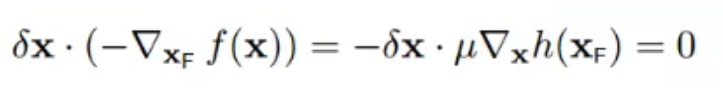
至此,我们就找到f(x)偏导数等于0的点,就是下图所示的两个关键点(它们也是f(x)与h(x)的临界点)。且必须满足以下条件,也就是两个向量必须是平行的:
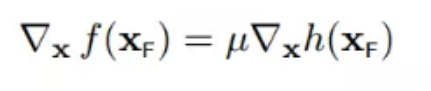
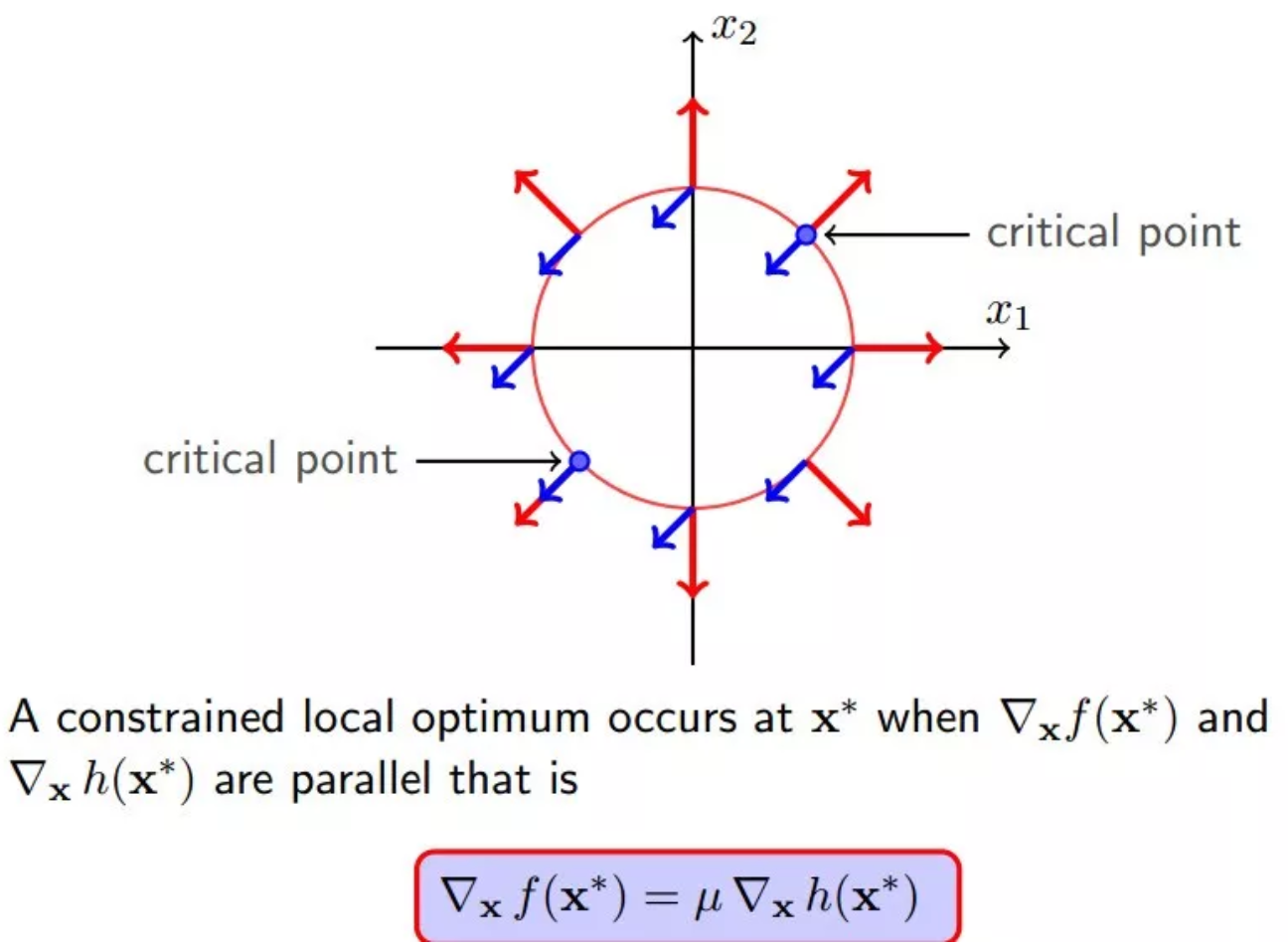
15 完全解码拉格朗日乘数法
至此,已经完全解码拉格朗日乘数法,拉格朗日巧妙的构造出下面这个式子:
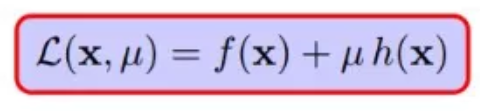
还有取得极值的的三个条件,都是对以上五个小节中涉及到的条件的编码

关于第三个条件,稍加说明。
对于含有多个变量,比如本例子就含有2个变量x1, x2,就是一个多元优化问题,需要求二阶导,二阶导的矩阵就被称为海塞矩阵(Hessian Matrix)
与求解一元问题一样,仅凭一阶导数等于是无法判断极值的,需要求二阶导,并且二阶导大于0才是极小值,小于0是极大值,等于0依然无法判断是否在此点去的极值。
以上就是机器学习最常用的优化技巧:拉格朗日乘数法的图形讲解,相信大家已经找到一定感觉,接下来几天我们通过例子,详细阐述机器学习的具体概念,常用算法,使用Python实现主要的算法,使用Sklearn,Kaggle数据实战这些算法。
16 均匀分布
导入本次实验所用的4种常见分布,连续分布的代表:beta分布、正态分布,均匀分布,离散分布的代表:二项分布。
绘图装饰器带有四个参数分别表示legend的2类说明文字,y轴label, 保存的png文件名称。
import pretty_errors
import numpy as np
from scipy.stats import beta, norm, uniform, binom
import matplotlib.pyplot as plt
from functools import wraps
# 定义带四个参数的画图装饰器
def my_plot(label0=None, label1=None, ylabel='probability density function', fn=None):
def decorate(f):
@wraps(f)
def myplot():
fig = plt.figure(figsize=(16, 9))
ax = fig.add_subplot(111)
x, y, y1 = f()
ax.plot(x, y, linewidth=2, c='r', label=label0)
ax.plot(x, y1, linewidth=2, c='b', label=label1)
ax.legend()
plt.ylabel(ylabel)
# plt.show()
plt.savefig('./img/%s' % (fn,))
print('%s保存成功' % (fn,))
plt.close()
return myplot
return decorate
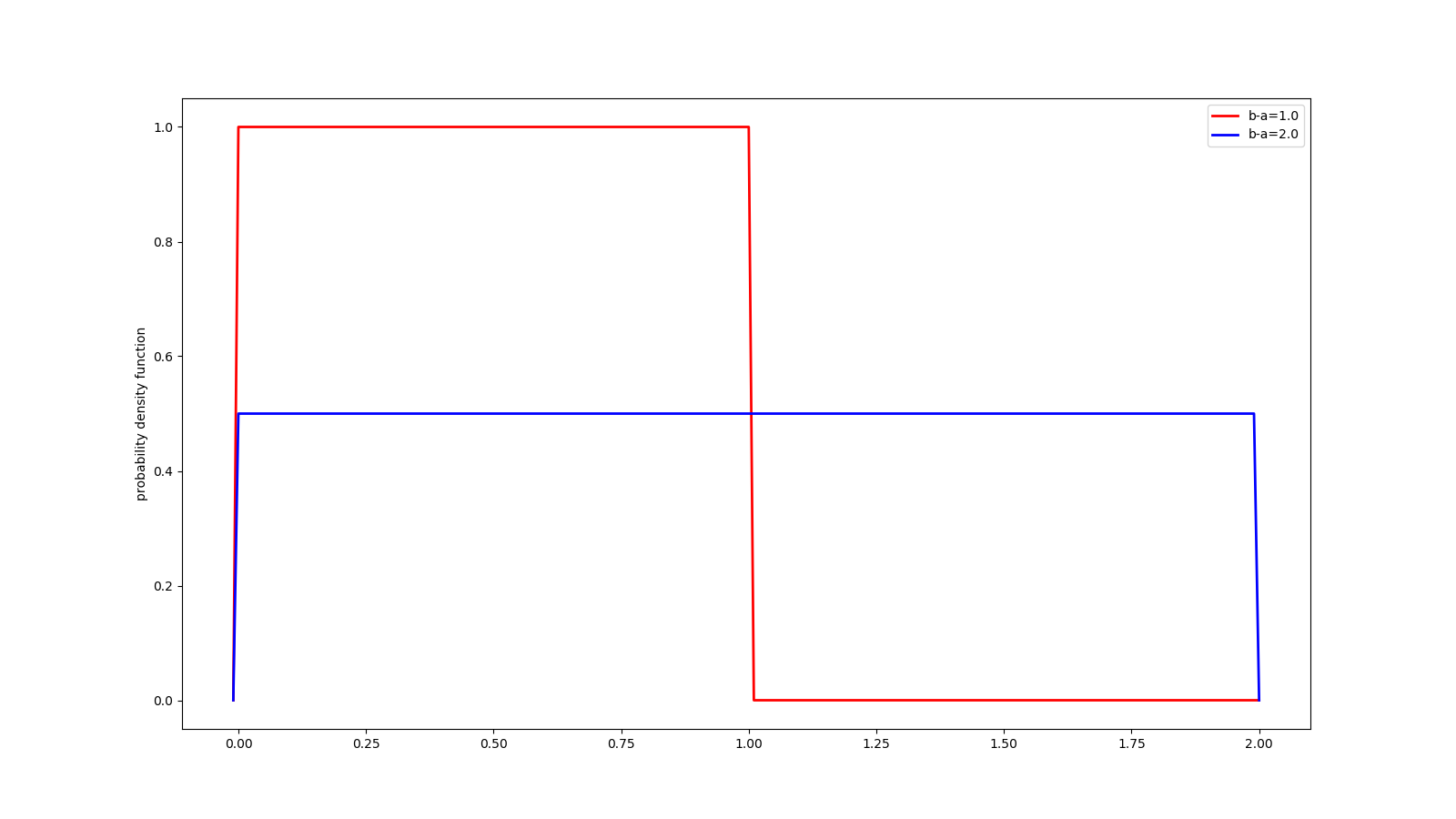
# 均匀分布(uniform)
@my_plot(label0='b-a=1.0', label1='b-a=2.0', fn='uniform.png')
def unif():
x = np.arange(-0.01, 2.01, 0.01)
y = uniform.pdf(x, loc=0.0, scale=1.0)
y1 = uniform.pdf(x, loc=0.0, scale=2.0)
return x, y, y1
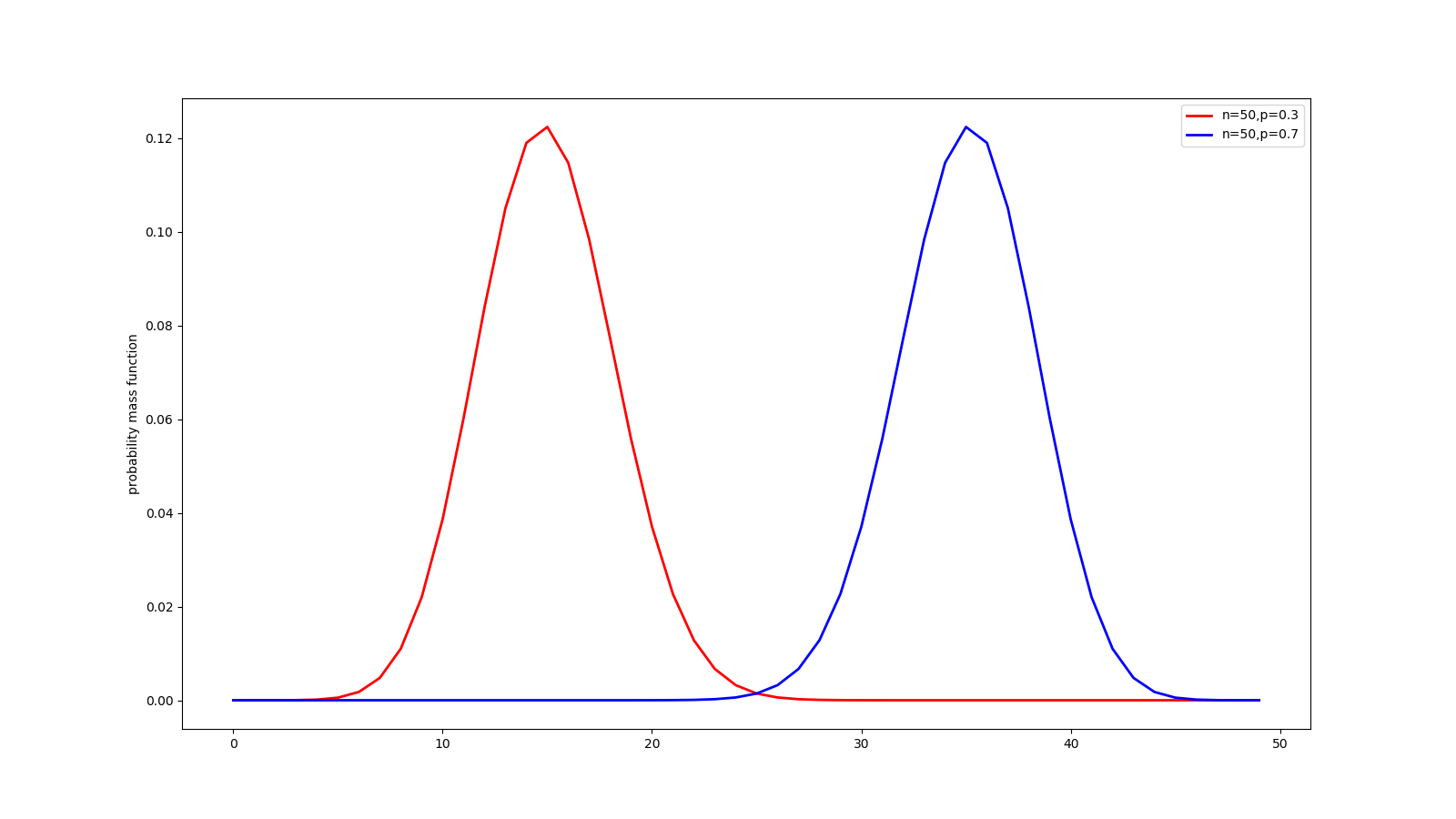
17 二项分布
红色曲线表示发生一次概率为0.3,重复50次的密度函数,二项分布期望值为0.3*50 = 15次。看到这50次实验,很可能出现的次数为10~20.可与蓝色曲线对比分析。
# 二项分布
@my_plot(label0='n=50,p=0.3', label1='n=50,p=0.7', fn='binom.png', ylabel='probability mass function')
def bino():
x = np.arange(50)
n, p, p1 = 50, 0.3, 0.7
y = binom.pmf(x, n=n, p=p)
y1 = binom.pmf(x, n=n, p=p1)
return x, y, y1
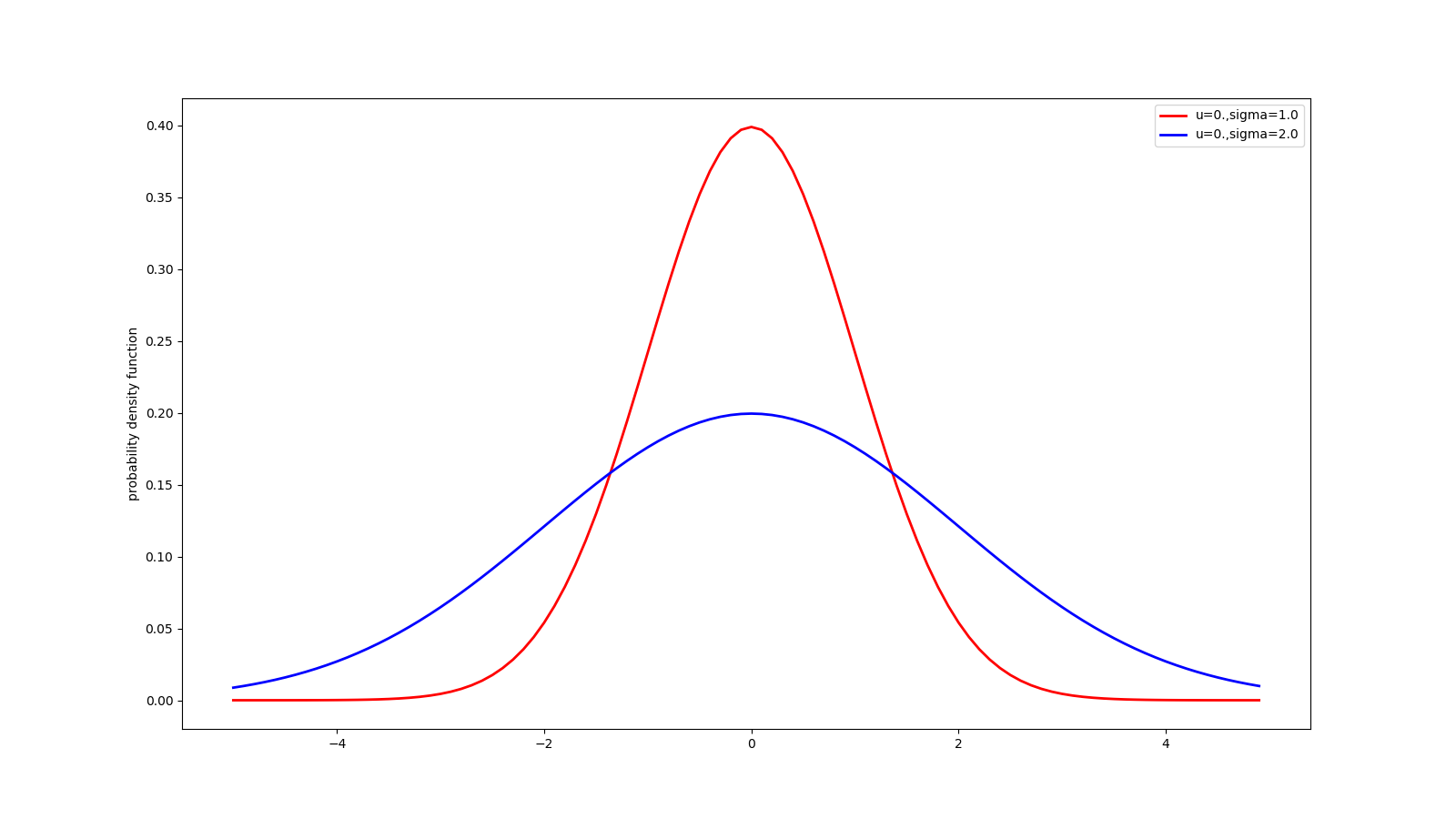
18 高斯分布
红色曲线表示均值为0,标准差为1.0的概率密度函数,蓝色曲线的标准差更大,所以它更矮胖,显示出取值的多样性,和不稳定性。
# 高斯 分布
@my_plot(label0='u=0.,sigma=1.0', label1='u=0.,sigma=2.0', fn='guass.png')
def guass():
x = np.arange(-5, 5, 0.1)
y = norm.pdf(x, loc=0.0, scale=1.0)
y1 = norm.pdf(x, loc=0., scale=2.0)
return x, y, y1
19 beta分布
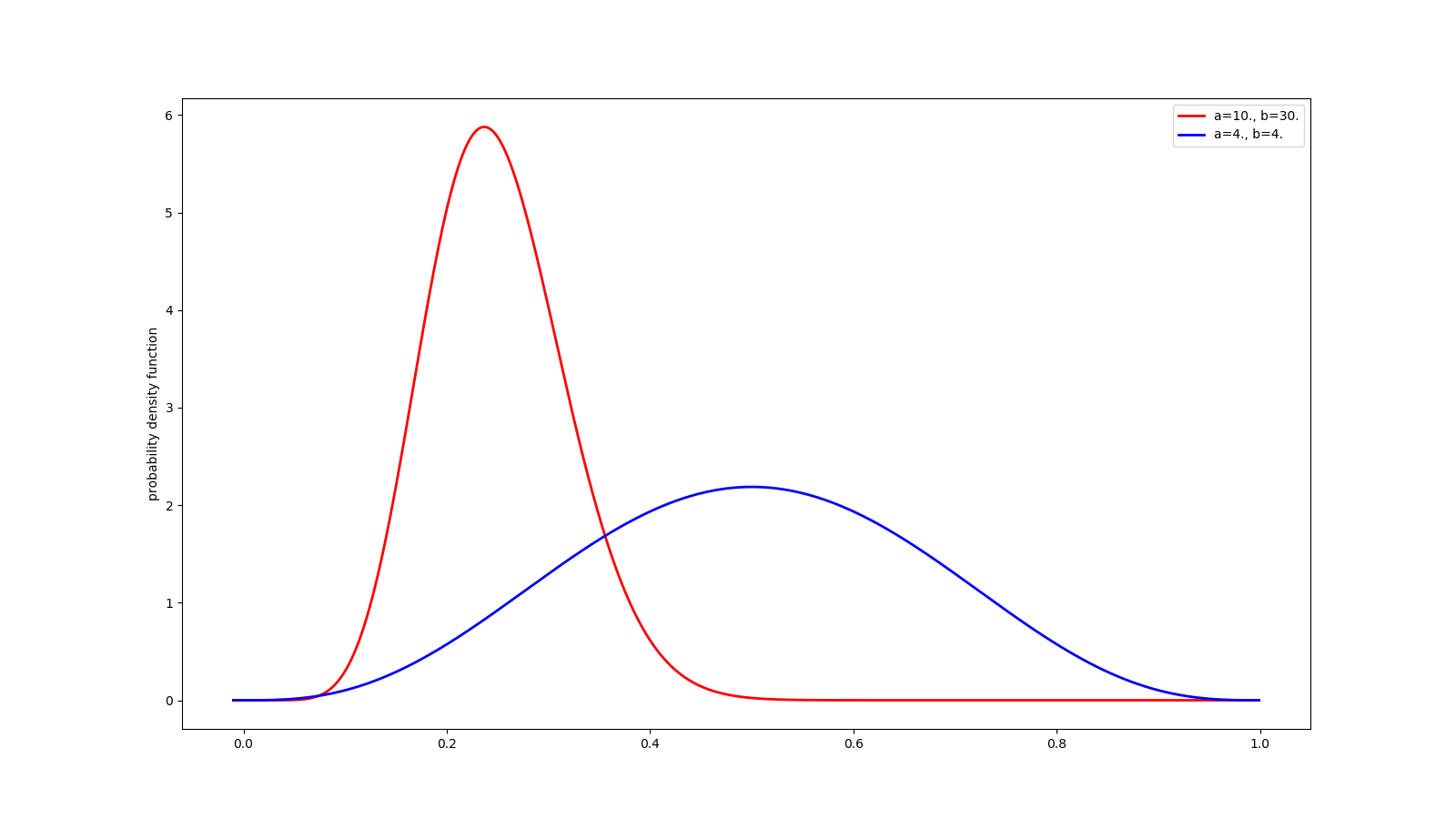
beta分布的期望值如下,可从下面的两条曲线中加以验证:
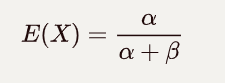
# beta 分布
@my_plot(label0='a=10., b=30.', label1='a=4., b=4.', fn='beta.png')
def bet():
x = np.arange(-0.01, 1, 0.001)
y = beta.pdf(x, a=10., b=30.)
y1 = beta.pdf(x, a=4., b=4.)
return x, y, y1